
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Encoder-Decoder Attention
- Regression Metric
- Pull Requests
- attention score
- conda install
- 구글검색엔진알고리즘
- TextRank
- Self attention
- Multi-class Classification
- cs182
- CommandNotFoundError
- 최대사후추정확률
- 머신러닝 순서
- Scaled Dot-Product
- MachineLearningWorkflow
- commit
- Keyword for TextRank
- Workflw
- Binary classification
- 머신러닝
- NLU
- github
- conda create env
- conda env
- Sentence for TextRank
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- conda
- Pull
- Activate
- 머신러닝 흐름
- Today
- Total
HalfMoon
[CS 182] Lecture 1: Introduction 본문

들어가기 앞서
CS 182 포스팅 시리즈는 UC Berkeley의 Sergey Levine 교수님의 유튜브 강의를 기반으로 만든 포스팅이며,
유튜브 링크와 슬라이드의 링크는 가장 하단의 Reference를 참고하면 된다.
강의적 특징으로는 수학을 기반으로 ML과 DL을 설명하며, 하나의 극을 보듯 연결되는 방식으로 이야기가 진행되니 참고하면 좋을 듯 하며, 모든 슬라이드를 설명하지 않고, 필요한 슬라이드만 발취하여 포스팅하였으니, 좀 더 자세하게 알고싶다면 하단의 링크를 참고하여 직접 보는 것을 추천한다.
Representation
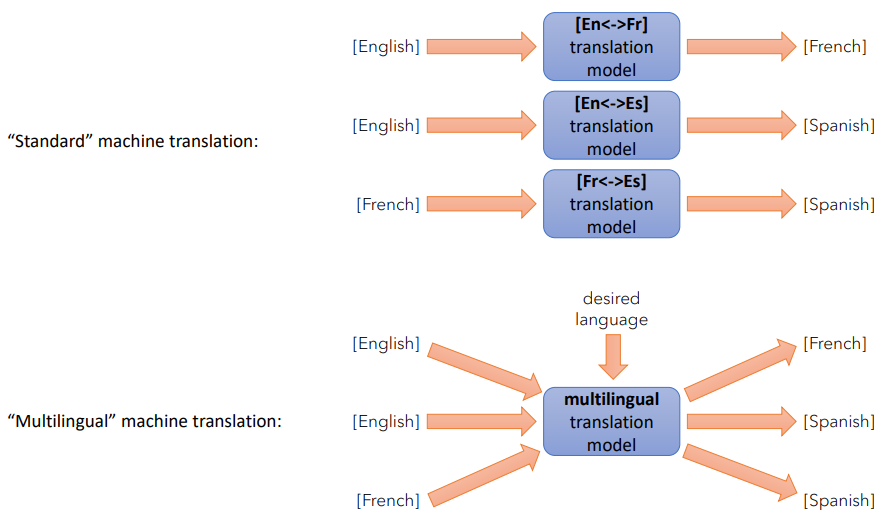
교수님은 인간의 언어를 Ai가 자유롭게 번역할 수 있는가?에 대한 질문으로 강의를 시작한다.
초반의 '번역' Task는 English:French, English:Spanish처럼 한 쌍의 pair를 통한 단일 언어 번역의 형태였다.
그리고 이러한 단일 언어들의 매칭을 통해 우리는 multilingual translation model을 만들어냈다.

multilingual translation model을 통해 알아낸 것들은 꽤나 유의미했다.
English:French, French : English 그리고 English:Spanish 를 충분히 학습한 모델이라면 학습시키지 않은 French: Spanish 의 번역이 가능했다는 점과 함께, 데이터가 부족한 '소수 언어'를 어느정도 이해할 수 있다는 점이다.

예를 들자면 위의 사진과 같은 실험이다.
영어 : 일본어 데이터와 영어:한국어 데이터를 학습한 모델의 경우, 한국어:일본어에 대해서도 어느정도 이해하는게 가능하다.
좌측의 숫자가 0에 가까울 수록 순수한 일본어 문장을 출력하고, 1에 가까울수록 순수한 한국어 문장을 출력한다.
이러한 조건에서 문법적으로 이전보다 점진적인 발전이 있었다는 부분이 꽤 흥미로운 부분이다.
추가적으로 조금 더 '표현'의 학습에 대해 흥미로운 부분을 공유해보자면,
위 내용이 있는 논문을 보면 혼합된 언어를 input으로 넣어도 output이 '말이 되는' 결과가 나오기도 했다.
이걸 해석해보자면, 모델이 학습할 때 단어 하나하나의 글자를 학습한 것이 아니라,
언어적으로 이러한 표현으로 쓰인다라고 학습한 것과 동일한 의미를 가진다.
이러한 결과를 통해 우리는 모델이 학습할 때 글자로써의 단어가 아닌, 언어로써의 표현을 학습한다는 점을 알 수 있다.
자, 그럼 CS182 강의에서 왜 이런 예시로 강의를 시작했을까?
이는 곧, 위의 예시가 딥러닝의 꽤나 흥미로운 부분이기 때문이다.

일반적인 번역 Task를 생각할 때 우리는 '생각'이라는 글자 자체를 같은 의미를 가진 다른 언어로 매칭하는 것으로 생각한다.
하지만 딥러닝에서는 '생각'이라는 단어의 의미 자체를 전달하는 것을 통해 다른 언어로 번역이 가능하다고 말한다.
때문에, 번역 Task에서 Pair를 이루는 단어를 찾아 해당 단어를 1:1 pair로 매칭하는 것 보다
1. ‘언어’가 어떻게 ‘생각’으로 인식되며,
2. 그 ‘생각’이 어떻게 ‘언어’로 전달되는지
위 두 가지 쌍을 알고 있고, 그 표현이 올바른 표현이라면 번역 Task가 더욱이 쉬워질 것이다.
그리고 이러한 방법을 통해 실제로 의미 있고, 이를 기반으로 우리는 복잡한 예측을 만드는데 적합한 입력 표현을 얻을 수 있다. 대표적으로는 x를 통해 y를 예측하는 회귀문제가 있을 수 있으며, 우리는 보통 선형 적합일 경우, 선형 결합을 사용하는 것 처럼 말이다.
때문에, 딥러닝의 강점은 데이터에서 자동으로 적합한 ' Representation'을 학습하는 능력에 있다.
Machine Learning & Deep Learning
그럼 이제 조금씩 Ai에 대해 들어가보자.
머신러닝이란, 데이터에서 관계를 요구하는 프로그램을 정의할 수 있도록 해주는 도구이다.
그리고 이러한 특징은 규칙 측면에서 원하는 것을 지정하는 것 보다, 원하는 것의 예시를 제공 하는게 더 편하고 효과적이다.
(데이터를 통해 규칙을 학습한다는 의미다.)
다시말해, 입력:출력으로 매칭되는 방식에서, 규칙이 복잡하며, 예외와 특수한 경우로 가득 차 있을 경우 머신러닝을 통해 규칙을 도출하는 것이 더 쉽다는 의미이다.
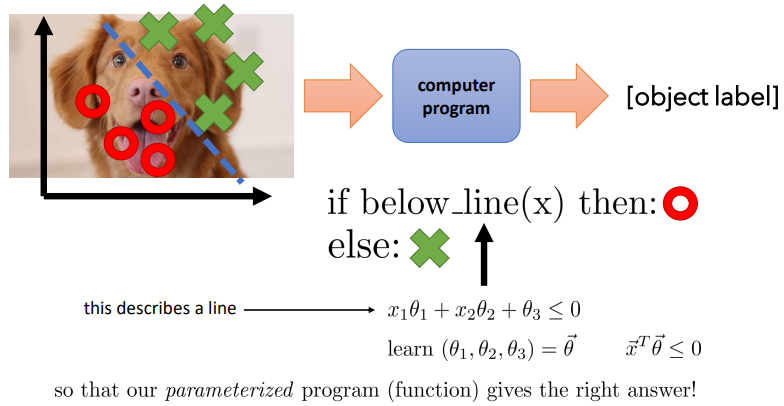
사진에 있는 수식을 늘 그랬듯 하나하나 뜯어보자.
1. $x_1\theta1 + x_2\theta2 + \theta3\le0$
$ x_1$과 $ x_2$는 2개의 변수를 의미하며
$\theta1$, $\theta2$, $\theta3$은 모델의 파라미터를 의미하며, 이때 $ \theta3$은 Bias를 의미한다.
예를 들어, 강아지 사진인지, 고양이 사진인지 구분하기 위해서는 $x_1$과 $x_2$가 몸의 크기와 눈의 모양이 되고,
$\theta$를 조절하는 것을 통해 강아지라고 예측하는 것이다.
결론적으로 위 수식은 로지스틱 회귀에서 decision boundary와 softmax를 통해 classification하는 수식이다.
2. $learn(\theta_1, \theta_2, \theta_3) = \overrightarrow{ \theta}$
의미는 꽤나 간단하다.
이는 $ \overrightarrow{ \theta}$ 가 모델 학습에 필요한 최적의 $\theta$를 찾는 과정을 표현한다고 생각하면 된다.
또한 $ \overrightarrow{ x}$와 $ \overrightarrow{ \theta}$에서 화살표는 $x$와 $\theta$가 벡터임을 의미한다.
즉, 여러 숫자 혹은 여러 스칼라의 순서가 있는 집합 수학 객체로 정의한다고 이해하면 된다.
여기에서 $ \overrightarrow{ x}$는 하나의 데이터 포인트에 대한 여러 특성 값을 포함할 수 있고, $ \overrightarrow{ \theta}$는 모델의 파라미터를 나타낸다.
3. $\overrightarrow{x}^\intercal\overrightarrow{\theta}\le0$
$\overrightarrow{x}^\intercal$ : 열 벡터 $x$를 전치하여 행 벡터로 변환
$\overrightarrow{\theta}$ : 전치된 $x$와 곱셈을 수행할 파라미터 벡터
위 수식을 통해 최적의 decision boundary를 찾아 데이터가 어떤 분류에 속할지 예측하는 과정을 수학적으로 표현는 단계이다. 결국 3개의 수식은 표기만 다를 뿐, 같은 표현을 서로 다른 말로 한 것과 동일하다.
또한, 위 세가지 수식은 간단하게 $f(x,\theta) = y$ 혹은 $f_\theta x = y$로 표현할 수 있다.
Shallow learning

$f_\theta (x) = y$에서 $\theta$를 고정하여 학습하는 것이 가능하며,$\phi(x)^\intercal \theta \le 0$의 표현으로 표현 가능하다.
예시를 들어 설명하자면, 바구니에 사과와 오렌지가 있을 때, 우리는 바구니에 오렌지만 남게하려고 한다고 가정해보자.
이 때, 우리는 오렌지의 특징을 모르기 때문에 사과를 바구니에서 빼내는 방식을 통해 바구니에 오렌지만 남게되는 형식이다.
즉, 위 사진의 예시처럼 사진에서의 '객체'를 골라내는 방식으로 사용 가능하다.

그리고 위의 단계를 응용하여 여러 층의 Layer를 쌓아 올린다면 그것이 우리가 말하는 딥러닝이 된다.
둘의 차이를 조금 더 표현해보자면, Shallow learning의 경우 x가 input으로 그대로 들어가 변화하는 느낌이라면,
Deep learning의 경우, x를 '표현'하기 위해 Layer를 통해 추상화된다고 생각할 수 있다.
Deep Leaning
이번 강의에서 DL에 대해서는 매우매우 간단하게 다루니, 해당 내용만 기입해보겠다.
DL의 특징
- Machine learning with multiple layers of learned representations
- The function that represents the transformation from input to internal representation to output is usually a deep neural network
- The parameters for every layer are usually (but not always!) trained with respect to the overall task objective (e.g., accuracy)
Deep learning의 제작에 필요한 것들
- Big models with many layers (과거, layer가 무조건적으로 좋았지만, 현재는 최적화의 문제)
- Large datasets with many examples
- Enough compute to handle all this
정리하자면 결국 데이터는 다다익선이고, 모델은 거거익선이다.
그리고 이를 위해서는 엄청나게 많은 비용(compute power)이 든다.

현대의 DL은 위 사진에서 언급하는 토픽 또한 가지고 있다.
1. 고용량(high-capacity) 모델과 대량의 데이터를 사용하여 표현을 획득 기능이나 표현을 수동으로 엔지니어링하지 않아도 됨
2. 학습 대 귀납적 편향(nature vs nurture): 대부분의 성능을 디자이너의 인사이트가 아닌 데이터에서 대부분의 성능을 얻는 모델
- 귀납적 편향: 모델이 효과적으로 학습할 수 있도록 모델에 구축하는 것. 효과적으로 학습하도록 모델에 구축하는 것
(이를 완전히 제거할 수는 없음!)
- 학습을 위해 지식을 구축할 것인가, 아니면 더 나은 기계를 구축할 것인가? 확장할 것인가?
귀납적 편향: 모델에 내장된 모델에 내장된 지식 또는 편견 학습을 돕기 위해 고안된,모델에 내장된 지식 또는 편향. 이러한 모든 지식은 위와 같은 의미에서 "편향"임. 어떤 솔루션은 더 가능성이 높고 어떤 솔루션은 가능성이 낮다는 의미에서 '편향'이라고 함. Bias
3. 확장 가능한 알고리즘: 종종 더 많은 데이터를 추가하고 더 많은 데이터, 표현 능력 및 컴퓨팅을 추가함에 따라 더 좋아질 수 있음
스케일링 : 데이터가 많아질수록 알고리즘이 더 많은 데이터와 모델 용량이 추가됨에 따라 모델 용량이 추가됨에 따라 알고리즘이 더 잘 작동하는 능력.
정리
딥러닝의 강점은 데이터에서 자동으로 적합한 ' Representation'을 학습하는 능력이다.
머신 러닝은 데이터에서 관계를 요구하는 프로그램을 정의할 수 있도록 해주는 도구이다.
규칙 측면에서 원하는 것을 지정하는 것 보다, 원하는 것의 예시를 제공 하는게 더 편하고 효과적인 특징을 가진다.
DL은 Machine learning with multiple layers of learned representations이다.
어떻게 표현하고, 학습할 것인가?
- $x_1\theta1 + x_2\theta2 + \theta3\le0$
- $learn(\theta_1, \theta_2, \theta_3) = \overrightarrow{ \theta}$
- $\overrightarrow{x}^\intercal\overrightarrow{\theta}\le0$
Reference
[Youtube]
Deep Learning: CS182 Spring 2021
[Slide]
CS182 git blogLearning: CS 182 Sp
ring 20
질문 및 틀린 내용에 대한 첨언은 언제나 환영입니다.
추가적인 지식 공유를 해주시면 너무나도 감사드리고,
질문하신 내용에 대해서 모르는 부분이 있으면 공부를 해서 답변을 달아보도록 하겠습니다!